As you have already known or noticed, currently we are in the era of artificial intelligence (AI) skills becoming critical for effectiveness and efficiency. Currently businesses/organizations are trying to have some benefit by using large-language models (LLMs). Besides having some efficiency by using some LLM Services, businesses are thinking how they can be effective by providing their own business within LLMs.
In this post, I will walk you through some strategies about being able to provide business values by using LLMs.
Currently, there are two big hot and important topics; Retrieval-Augmented Generation (RAG) and fine-tuning… They are both a strategic way of having some custom business data in generative AI concept. So, within those two strategies, businesses can provide their business values more efficiently in AI aspect. Both strategies have their pros and cons, and of course their usage depends according to the requirements.
Retrieval-Augmented Generation (RAG)
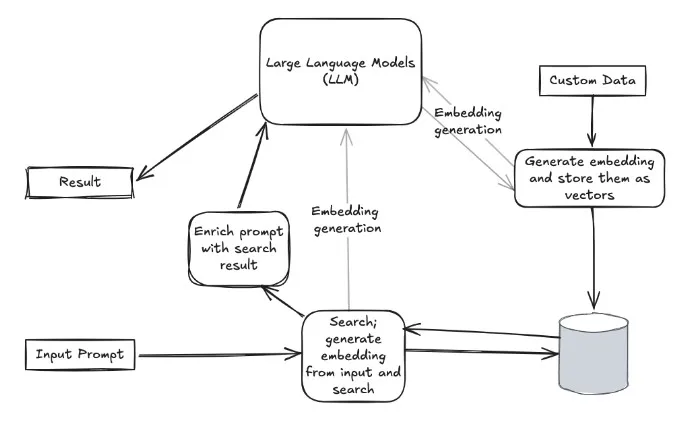
RAG is a method where an AI model fetches an extra information from a large data store before providing an answer to a question. For more simple term, it’s like the AI saying, “Let me Google this real quick” before giving a response…By “Google”, it means doing a quick search in a data store which contains well defined data chunks of specific context(s).
In this context, data store contains organizations unique data, some kind of representation of their business values. In RAG, as its name defines, there are two steps in this generative AI strategy, “Retrieval” and “Augmented”. Mainly the data chunks are retrieved with some algorithms in data store tier. And then retrieved results are augmented by some LLM response for much effective responses. So, retrieval is important step to be able to provide good data to LLM. To be able to retrieve much correct and relevant data, having a data in that way is also very important. Vector databases are main actors for this step. Mainly, by design, vector databases stores data as array of numbers which are called vectors. And within vector databases, those vectors can be queried according to similarities. So, similar data can be retrieved more efficiently within vector databases.
To be able to understand similarities in data, LLMs are used to extract the similarities from data chunks. When having some business data in the vector database, they need to be stored as embeddings. For example, words with similar meanings (like “cat” and “dog”) will have embedding (vectors) that are close to each other while unrelated words (like “cat” and “car”) will be farther apart.
There are some LLMs for embedding. So, much relevant data is stored as embedded in vector databases. After retrieving much relevant data, then augmenting that data with LLM will create much effective result.
Ok, let’s make an example flow to make RAG easier and clearer to follow.
Step 1: Collect all your business data
- PDFs, Words, Web pages, data records…etc. , they can be product documents, user-stories, tickets, wiki pages.
Step 2: Prepare the business data
- Prepare the data in clean format; remove duplicates, split large ones to small chunks (This is good for AI to process them quickly and create embeddings)
Step 3: Add tags
- This is an optional step, but having some labels/tags for data chunks helps system search more effective. And as you know, we all do these to provide more effective business, right?😀
Step 4: Convert data chunks to embeddings
- By using an embedding model, convert data into vectors with some similarities in it. Mainly those vectors will represent the data and used for search.
Step 5: Store vectors in a vector database
- Store data and its embedding in vector databases like Couchbase, MongoDB, Azure Cosmos DB, PostgreSQL…many more.
Step 6: Augment the result from vector database
- An asked question is converted into embeddings with some LLM model
- Embeddings are searched in the vector database
- Similar data chunks are retrieved
- Retrieved data is augmented with LLM to have more reliable answer.
I think that having a RAG strategy is like an additional plug-in for a solution. No additional LLM training or additional big computing is required. I think the most challenging part might be preparing the data. Not hard, but some dirty work might require if businesses does not have a structured or organized data in place.
After having structured and organized data, RAG strategy provides more help within data updates/changes. Whenever data is changed, data store can be updated. And this will provide more up-to-date data in results.
Fine-tuning
Fine-tuning is another method to provide some business data within a model. Within fine-tuning, a pre-trained model is taken and re-trained a bit more with a specific set of business data. For more simple term, it is like asking the AI to complete some courses and have more info about a topic before giving a response…By “course”, teaching AI the business’ knowledge.
It is a little bit tricky then RAG method. It requires some deep knowledge about training. And, for effective results, taken pre-trained model should be good and a specific one. But as you can guess, it is not logical or easy to find for now. For example, if you are doing some business about health insurance, then it would be much effective to use a pre-trained model about health context. Of course, some existing pre-trained models like Llama, Phi…etc. can be used, but in that case if your data or business not good enough the results might be not effective as you wish. Because most are trained with some limited generic text-based data, they might not be effective.
Even there are good pre-trained models for some businesses, as I said good knowledge about training steps are required. Doing trainings with some parameter setup and then doing tests require some time. Because training might take some time (more than a week or two…), it is hard to provide up-to-date data within results if the business has lots of data changes in time. And all these processes will require also some good computing resources which means “costs”.
I don’t want to create an impression that “fine-tuning” is a bad strategy. But I think, within current LLMs, it is not a good starting strategy to be effective for a business by fine-tuning. But of course, if a business is mature enough to do data engineering and machine learning then they can create their own models and do re-trainings with some specific domain data to be more effective.
I believe that within next months or years, big global organizations like World Health Organization (WHO), Unicef, Greenpeace, EU, Unesco..etc. might publish LLMs about specific domains as they publish reports. And those might help businesses to do fine-tuning for their business data.

*Some open-sourced models can be found in Hugging Face
Conclusion
“RAG” is like AI is doing a Google search first before responding. “Fine-tuning” is like tuning the guitar strings first before playing a song. Both strategies have pros and cons. And both pros and cons depend on requirements and maturity of the businesses. But if it is asked to me, I would vote for RAG for effectiveness and efficiency for the business value for now. I can also summarize my thoughts as below.
| RAG | Fine-tuning | |
| Main concept | AI fetches business data | AI trained with business data |
| Much better for | Frequently changed data | Expertise in static data |
| Cost | Low | High |
| Required LLM expertise | No | Yes |
If you have some thoughts, feedback or real field experiences feel free to share below as comment. See you in another post…👋🏼